

Every vendor involved in security talks about risk. But risk as a concept is tough to grasp – it just means something bad can happen to your organisation, not that it will necessarily happen. Somehow, you’re supposed to equate the presence of some level of risk with an equal level or priority within IT. Often, risk (and the needed response) can be obvious. For example, if you’re being hit with ransomware via unpatched software, guess what you’re going to be doing next? In that case, the risk was high should you do nothing. So, the prioritisation of your time is simple to deduce.
Unfortunately, most of the time risk simply isn’t that obvious. It’s more about a threat potential than an actual occurring event. What is helpful to IT is an ability to quantify just how much risk we are talking about. Once you have an idea of what the potential risk is in tangible terms, then, and only then, can you truly begin to prioritise your actions.
One solid way is to understand risk at to look at it in terms of the actual GBP cost. In simple terms, you don’t just want to know you have “x amount of risk” – which effectively means nothing without a point of reference – you want to know you have a specific risk cost tied directly to information, assets, the state of security measures, etc. from within your organisation.
Understanding risk in real terms
Put another way, if you know your roof needs repairing, your guttering needs fixing, there is a risk associated with not addressing these needs. When you realise the cost associated with not doing these tasks – such as if you don’t fix the roof, you’ll have leaks into the house that will cost you thousands instead of just patching the roof for £500 – you have much more context around the actual risk. And an idea of what the cost of that risk is should you choose to do nothing.
So, how do you calculate the GBP cost of risk for your organisation?
Let’s look at it the same way SME IT Security Liability Assessment does.
You begin with the foundation of trusted industry data – Ponemon’s annual Cost of a Data Breach report (https://www-03.ibm.com/security/uk-en/data-breach/). This report helps to paint a picture of what each type of data would cost your organisation were it to be involved in a data breach. For example, a certain piece of data might cost your organisation £201 per record, based on industry data – it all depends on factors like the data type in question (e.g. credit card, health record, etc.), the industry sector you’re operating in and your location in the world.
Built on that foundation is the ability to look for sensitive data lying unprotected on endpoints within your organisation. While sensitive data is normally found centrally on servers as part of an application database (HR, CRM, etc.), many organisations have more sensitive data stored on endpoints than they realise. A scan for various data formats (e.g. ## ## ## ## # for a national insurance number) across all your endpoints would yield every machine that has data stored on it. Tying those to a specific cost per record, makes it relatively straight-forward to calculate the potential risk in the form of liability should those records be compromised.
Risk vs vulnerability
But you can’t stop there. Let’s say a machine has 1,000 records on it. That doesn’t mean it will specifically be involved in a data breach. So, you can’t necessarily say every record found on every machine will be involved either. To assess the risk level of a given endpoint, the degree of vulnerability (in the form of checking to see if a machine is patched for known vulnerabilities) must be assessed, with a risk score – in this case the National Institute of Standards and Technologies’ Common Vulnerability Scoring System (CVSS) – applied to the endpoint. Even machines with zero records still need to be assessed, as unprotected endpoints can act as footholds for external attackers working to penetrate an organisation looking for valuable data.
So, the formula is simple:
Number of unprotected records x cost per record x CVSS Score
The challenge in calculating risk is the ability to put it all together – centrally scanning endpoints for sensitive data across your network, associating those data types to current industry data to reflect your true cost and then aligning each instance of sensitive data with a vulnerability score of the machine it’s on.
The result looks something like this.
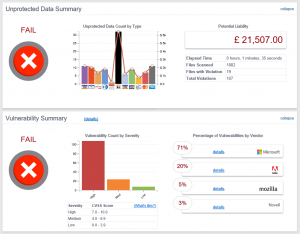
In this case, you can see the counts of unprotected data based on the various types of information using the scale at the left of the chart (for example, there are 11 Visa card numbers), along with a per-type calculated risk cost using the scale at the right (putting the risk cost of those Visa card numbers somewhere between £2,000 and £3,000), and the total potential risk liability at the far right (calculated by totaling the risk costs and applying the CVSS) for a given endpoint.
Risk determines response
Without knowing just how much is at risk (from both “what’s exposed” and “how exposed are we” standpoints), you can’t establish how much of a priority to place on specific security concerns. Sure, you know that not all your machines are patched, and that there will be some amount of sensitive data out there on your network, but without correlating the two, you’ll probably think your network is OK, and that no response is needed.
Putting a GBP cost on your risk gives you perspective on the problem – where to focus and how much to focus. Using a solution like SME IT Security Liability Assessment , you can quickly ascertain the cost of your risk and where that risk exists within your organisation.
In my next blog, I’ll continue the topic of risk but talking about what actions SMBs should take with this information.
To find out more about SME IT Security Liability Assessment , click here.


